【AWS RDSの悲鳴】WordPress Popular Postsが重い原因を分析してみた

やっぱり犯人はこのプラグインだった^^;
どうも、ハザマです!
ワードプレスの人気記事集計プラグイン「WordPress Popular Posts」ですが、よく「動作が重い!」と話題になっていますね。
僕が仕事でサーバ状態を監視しているサイト(注:このサイトではありません)でもそういったことはよくあるのですが、正直なぜそんなことになるのかよく分かっていませんでした。
今回、そのサイトでおきた事件をきっかけに原因を分析してみましたので、ご参考になればと思います。
僕のこのサイトと話が混在するとややこしいので、事件が起こったサイトを『サイトB』とします。
スポンサーリンク
サイトBにて事件発生
ある日の夕方、サイトBの動作がとても重くなりました。
トップページにいたっては、上部のサイトロゴしか表示されない有様に。。。
さらにF5キーを押して更新したところ、サイト全体が以下のようなメッセージで埋め尽くされました。
Warning: mysqli_real_connect(): (○○○○/△△△△): Too many connections in /var/www/html/wp_データベース名/wp-content/db.php on line ◇◇◇◇
いまサイトの情報等は別の文字に置き換えていますが、実際にはデータベース構造が剥き出しになっていました^^;
このメッセージは、『データベースからの情報取得に負荷がかかっているぞ!』という意味です。
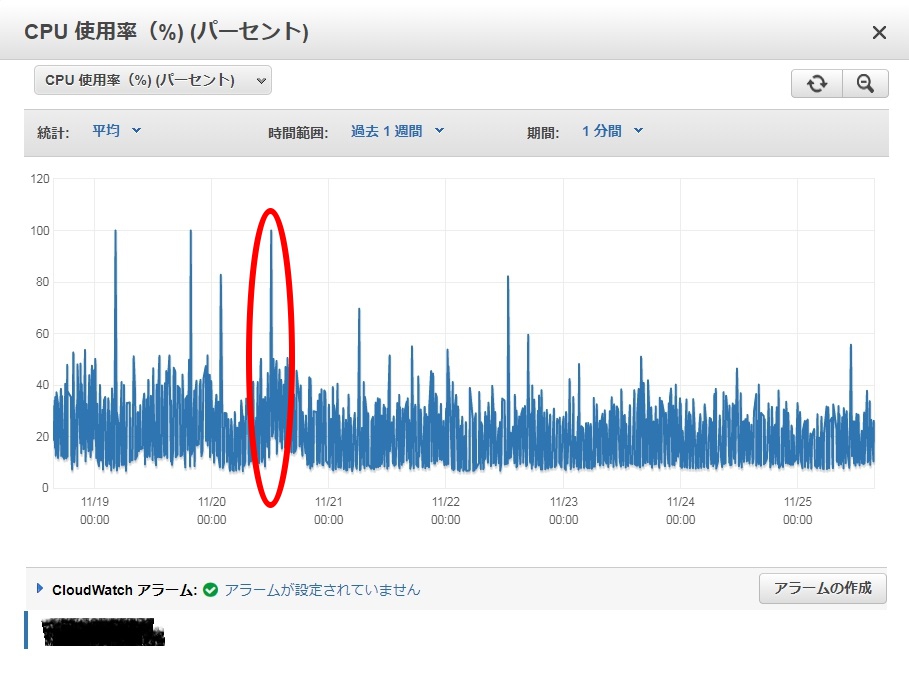
このためサイトBのデータベース監視ツールを確認したところ、CPU負荷が100%に!
えらいこっちゃです。
以下が、CPU使用率の画像です。(赤枠の時間帯に、異常に気付きました^^;)
サイトBの環境
サーバ環境として、AWSを利用しています。
CPU負荷等の画像は、そのサービスのRDSを監視したものです。
※ちなみに、データベースは『Aurora MySQL』を採用しています。
AWSとは?RDSとは?
AWSとは、アマゾン ウェブ サービス(Amazon Web Services)の略称です。
RDSとは、AWSが提供しているリレーショナル データベース サービス(Relational Database Service)の略称です。
データベースは、サイト運営のために記事等のデータを保管している倉庫と考えていただいて構いません。
ややこしい話もいっぱいあるので、ここではあまり深く触れずに進めます。
今回の事象の原因
結論から述べると、集計データが【1ページビューごとにデータベースへ登録されるている】ことが原因です。
通常は各記事ごとに1日1回ページビュー数を集計してデータベースへ登録していたはずなんですが、ある日を境に登録状況が変わっていました。
以下画像は、このプラグインが使っている【どのページが何回見られたか】という数値を保管しておく場所(テーブル)の登録履歴から、1件の記事だけに絞ってみたものです。
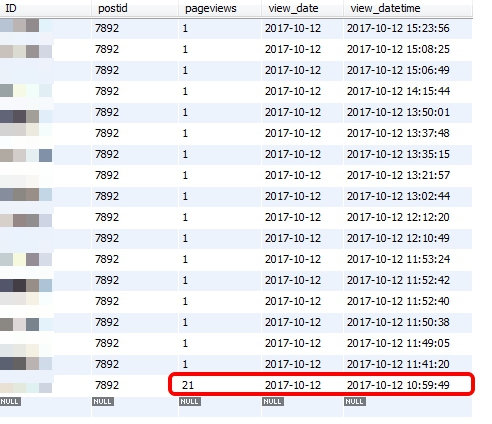
補足しておくと、
postid:記事のID
pageviews:ページビュー数
view_date:ページが見られた日
view_datetime:そのデータを登録した日時
です。
登録日時を見てみると、連続して登録(書き込み)されているのが分かります^^;
基本的に、データベースへの読み込み回数や書き込み回数は少ないほうが負荷は下がり、多くなれば上がります。
この登録履歴を確認すると、サイトBに関しては2017年10月12日の10時58分ごろまでは、それほど負荷は無かったのだと考えられます。
この日付以前は、1日1回の登録履歴しか残っていませんでした。(他の記事もほぼ同じ時間から変化しています。)
なぜその時間から変わった?
これは推測ですが、以下のうちいずれか、または全てがあったと考えるのが妥当かと思います。
・負荷が始まった時間付近で、プラグインのアップデートを実施した
・WordPressバージョンのアップデートを実施した
・当該プラグインの何らかの設定変更を行なった
僕はサイトBを管理したり記事を投稿したりしているわけではないので、こればかりは特定できません。
管理者にも確認してみましたが、覚えていないということでした。(そりゃそうですよね。。。)
原因になぜ気付いたか
データベース内のテーブルについて、まずはレコード数(行数)の多いものから確認してみようと考えました。
その結果が以下の画像です。
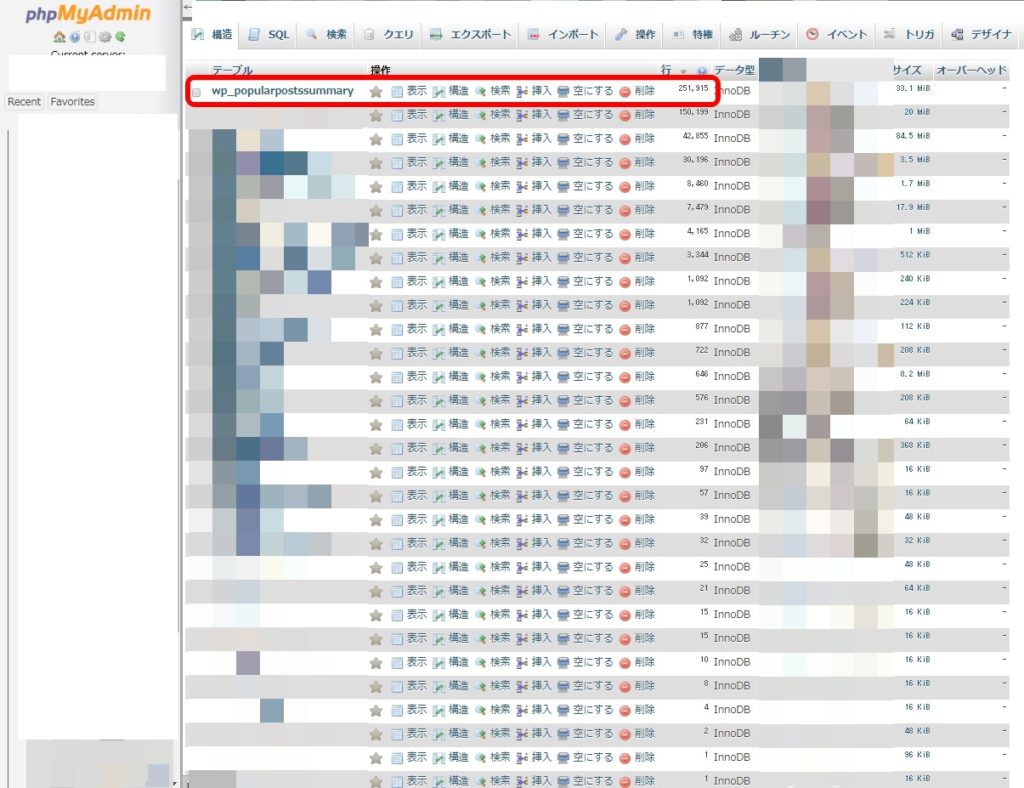
『wp_popularpostssummary』というテーブルは、人気記事一覧の情報を格納するところです。
・・・ええ~っと、25万行?笑
このテーブルを数ヶ月前に確認したときは、3万行程度でした。
これは異常だと思いテーブルの中身を確認した結果、例の1ページビューごとに。。。という原因を発見したということです。
運よく、一発で原因を発見できました☆笑
スポンサーリンク
スポンサーリンク
今回とった対策
1.サーバ(RDS等)を再起動
ワードプレスの管理画面すら開けない(例のエラーメッセージでいっぱい)という状態だったので、まずはサーバ関係を全て再起動しました。
2.原因のプラグインを停止
サーバ再起動後に管理画面へログインし、プラグイン「WordPress Popular Posts」を停止しました。
それ以外のものは設定も触らずに、ひとまず原因を特定させようとしました。
結果
サーバへのアクセス状況は減り、ページも速やかに表示できるようになりました。
今回話題には挙げませんでしたが、一応CPUクレジット残高の状況も載せておきます。
CPUクレジットを使ってCPUの使用域をバーストさせることが出来る契約をしています。
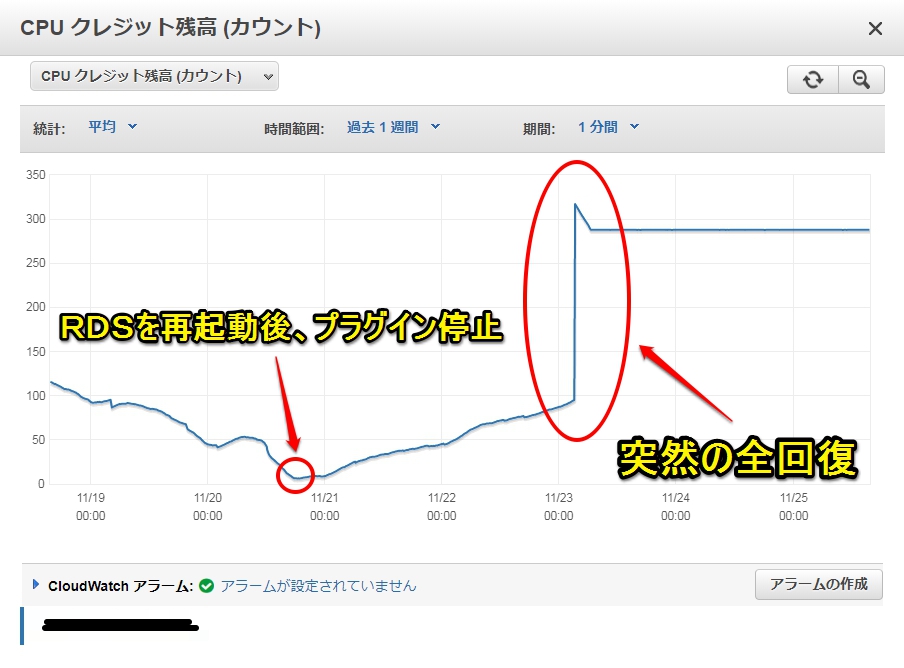
CPUクレジット残高ぎりぎりの状態で再起動をかけました。
危なかった。。。(汗)
一日中アクセスがあるホームページに関しては、こういったタイプの契約は合っていないのでは?という勉強にもなりました。
ちなみに数日後に突然クレジットが全回復していますが、原因は調べてません。
他で管理しているRDSでも同様の回復があったので、AWS全体の話だという理解でとどめてます。
反省点
発見が遅れたことの原因として、定期的な監視をしていなかったことが挙げられます。
定期的な監視をしていることで異常兆候をつかみやすくなりますし、普段の状態というものを知ることが出来ます。
普段の状態がどうなのかを理解していないと、不具合発生時に原因の特定が遅れてしまいます。
ホームページの動作が遅いという事象1つに関しても原因はひとつとは限らないので、CPU使用率やデータベースへのアクセス回数などを見渡して、瞬時に見つける必要があります。
例えば、「普段のCPU使用率は20%以下なのに今日は50%を超えている。おかしいぞ!」などですね。
そういったことを踏まえて、今後は定期的な監視をしていきます^^
その他の対策
こちらのブログで紹介されているように、プラグインの設定見直しが必要な可能性もあります。
何日分のログを残しておくか?ということも考えるべきでしょう。
後日談
実は数日前から、再びこのプラグインを復活させて様子を見ています。
いまのところCPUクレジットに急激な減少はありませんが、やはりアクセスが集中すると結構負荷がかかりCPUの使用率は上昇しています。
その様子は、また別の機会にお届けしたいと思います!
それでは♪
スポンサーリンク
スポンサーリンク





